Jedną z największych zmian w makroarchitekturze AMD Zen 3 jest nowa organizacja rdzeni i wspólnych dla nich pamięci podręcznych. Poprzednio cztery rdzenie dzieliły jedną pulę cache L3. W Zen 3 – z powodów, o których pisałem w poprzedniej publikacji – zachowano tę samą pojemność cache L3 w stosunku do liczb rdzeni. Rdzenie i towarzyszące im 2-megabajtowe segmenty wspólnej pamięci pogrupowano jednak po 8.
Zen 1
Zen 2
Zen 3
Pamięć podręczna L2
512 kB
512 kB
512 kB
Pamięć podręczna L3 w CCX
8 MB
16 MB
32 MB
L3 wspólna dla…
4 rdzeni
4 rdzeni
8 rdzeni
8 rdzeni i ich pamięć L3 tworzy CCX – core complex. Pamięć L3 w ramach jednego CCX jest wspólna dla wszystkich rdzeni.
Dostęp do pamięci L3 trwa w Zen 3 nieco dłużej, niż w poprzednich generacjach. Im większa pojemność cache, tym dłuższy czas dostępu do niej. Choć L3 w Zen 3 jest zbudowana prawie tak samo, jak w Zen 2, danych trzeba szukać w dwa razy większej pojemności, a do dużej części pamięci jest po prostu fizycznie dwa razy dalej.
Nawet z tym spowolnieniem pamięć L3 w Zen 3 jest wybitnie szybka i pojemna w porównaniu do innych wysokowydajnych procesorów, nie tylko tych o architekturze x86.
Wspólność cache L3 ma dwa główne efekty. Po pierwsze, o ile inne rdzenie nie korzystają intensywnie z pamięci, jednowątkowy program może mieć dostęp do znacznie większej puli szybkiej pamięci: może zająć całą pojemność L3. To daje wzrost wydajności niezależny od systemu operacyjnego, rekompilacji czy innych programistycznych technk optymalizacyjnych, dostępny nawet dla starych i kiepskich technicznie programów. Po drugie, wspólna pamięć (podręczna lub RAM) jest jedynym sposobem na to, żeby dwa wątki programu, przypisane do różnych rdzeni, operowały na tym samym obszarze pamięci.
Komunikacja między rdzeniami w Zen 3
Przytoczę jeszcze raz analogię z maszyną Turinga: rdzenie procesora wielordzeniowego można porównać do wielu maszyn Turinga operujących na jednej taśmie. Nie mają żadnego sposobu na skomunikowanie się ze sobą innego niż zapisanie czegoś na taśmie. Kiedy ten sam fragment taśmy trafi przed głowicę innej maszyny, nastąpi jedyna możliwa między nimi komunikacja.
W ten sposób przepustowość i opóźnienie w komunikacji między rdzeniami są nierozłącznie związane z dostępem do najszybszej wspólnej dla nich puli RAM-u. W tym przypadku to wspólna pamięć podręczna L3.
Po drugie, jeden wątek ma do dyspozycji więcej pamięci dla siebie
Opóźnienie w komunikacji między rdzeniami nie jest jednolite w ramach jednego bloku CCX. Niewielkie różnice w kolorze wewnątrz dwóch dużych zielonych pól – par wątków znajdujących się w jednym CCX – nie są błędem ani artefaktem pomiarowym. Zmierzenie go inną metodą potwierdza, że niektóre pary rdzeni komunikują się wolniej niż inne. Przyjrzałem się opóźnieniu w komunikacji między rdzeniami w ramach jednego CCX:
W tym teście wątek przypisany do jednego procesora rezerwuje kilkaset megabajtów przestrzeni adresowej, a następnie modyfikuje 192 kB – to ma na celu sprowadzenie takiej części adresów do pamięci L2, która w Zen 3 jest prywatna dla jednego rdzenia. Następnie drugi wątek, przypisany do innego procesora, próbuje odczytać te dane, i mierzy jak długo to trwało. Ten test powtarza się wielokrotnie dla różnych 192-kilobajtowych części zarezerwowanej przestrzeni adresowej. Średni czas dostępu jest podany na wykresie (tym razem, dla dokładności, w cyklach zegara, nie nanosekundach).
Adresy w pamięci są w procesorach Zen, Zen 2 i Zen 3 równomiernie rozdzielane pomiędzy segmenty pamięci cache L3. Ponieważ test wykorzystuje nie jedną linię z cache, ale duży obszar, spodziewam się, że dane są pobierane ze wszystkich segmentów. Fizyczna odległość między segmentami L3 nie powinna mieć wpływu na średni czas dostępu.
Rozkład opóźnień jest nieco skomplikowany przez to, że przetestowałem 12-rdzeniowy procesor, który w każdym CCX ma 2 rdzenie i 2 segmenty cache L3 wyłączone. Być może każdy CCX w każdym Ryzenie 9 5900X ma inny rozkład opóźnień w zależności od tego, które 2 spośród 8 rdzeni wyłączono.
Pary rdzeni są z grubsza skupione wokół trzech poziomów opóźnień: trzy pary są „najszybsze”, trzy „najwolniejsze”, a dziewięć ma średni czas komunikacji ze sobą. Wyniki testu nie pozwalają jednoznacznie określić, jak jest zrealizowana komunikacja wewnątrz CCX. AMD tego nie ujawia, a różni komentatorzy i recenzencji proponują albo pełen crossbar (połączenie każdy-z-każdym), albo dwa 6-punktowe crossbary, albo magistralę pierścieniową (patrz przypisy).
Wydaje się, że magistralę pierścieniową można wykluczyć. Nie ma sposobu na usunięcie 2 przystanków z pierścienia o 8 lub więcej przystankach w taki sposób, żeby pozostawić tylko 3 najkrótsze trasy. Na podobnej zasadzie można wykluczyć pełen crossbar oraz dwa równoległe 6-klientowe crossbary. Jak sądzę, w Zen 3 zastosowano jakiś dwu- lub więcej etapowy crossbar.
W praktyce różnica w czasie komunikacji między rdzeniami nie ma istotnego znaczenia. Pomiędzy najszybszą a najwolniejszą trasą jest ok. 20 cykli różnicy – tyle samo, co w 8-rdzeniowym procesorze Coffee Lake/Comet Lake, ale najwolniejsza trasa w Zen 3 jest tak długa, jak najkrótsza w Coffee Lake. Komunikacja w ramach jednego CCX jest ok. dwukrotnie szybsza od komunikacji pomiędzy różnymi CCX, ma znacznie większą przepustowość i kosztuje znacznie mniej energii. Dlatego choć warto dbać o przypisanie wielowątkowych programów do rdzeni znajdujących się w jednym CCX (systemy Windows 10 i Linux robią to automatycznie), to nie trzeba brać pod uwagę różnic pomiędzy rdzeniami wewnątrz CCX.
Przypisy i źródła
Wszystkie testy zostały wykonane w systemie Ubuntu 20.10 z jądrem Linux 5.8.0. Numeracja wątków logicznych została zmieniona na tę odpowiadającą systemom Windows: sąsiadujące numery odpowiadają dwóm wątkom SMT jednego rdzenia.
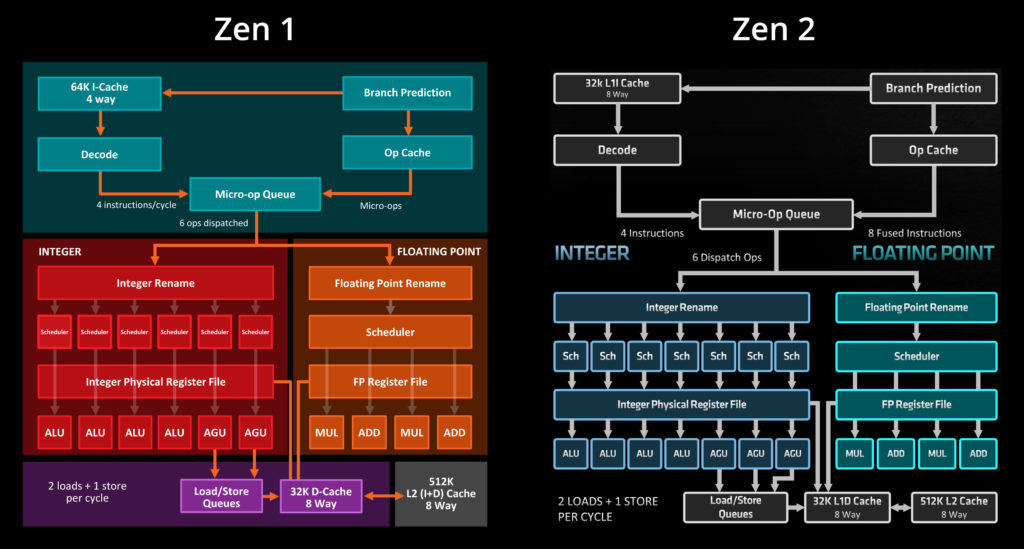
W ciągu niecałych czterech lat AMD zaprezentowało i wykorzystało w różnych procesorach trzy kolejne wersje architektury Zen. Pierwsza była solidną podstawą do budowy wielordzeniowych procesorów i przetarcia szlaków w budowie niejednolitych, rozdzielonych na wiele jąder procesorów. Nie była pozbawiona wad – procesory z architekturą Zen nie były tak wydajne w zastosowaniach jednowątkowych, jak wydane w tym samym okresie procesory Intela. W architekturze Zen 2 znacznie ulepszono możliwości wykonywania obliczeń wektorowych i zmiennoprzecinkowych. Wykorzystano też możliwości stworzone przez proces produkcyjny klasy 7 nm do radykalnego rozbudowania pamięci podręcznych, a przy tym poczyniono następny krok w rozdzielaniu funkcji procesora pomiędzy osobne jądra krzemowe.
Po stosunkowo niedługim czasie AMD zaprezentowało architekturę Zen 3. W makroarchitekturze nie poczyniono zasadniczych zmian – nowe procesory AMD są zbudowane w bardzo podobny sposób, co poprzednia generacja. Jednak rdzenie x86 zostały gruntownie zmienione. Mimo wielu podobieństw różnią się od Zen 2 bardziej, niż dwie pierwsze generacje różniły się od siebie nawzajem.
Budowa architektury Zen 2, zarówno na poziomie rdzeni x86 jak i na poziomie całego procesora (makroarchitektura), została w dużym stopniu ukształtowana przez postęp w litografii. Zmiana procesu produkcyjnego pozwoliła zmieścić znacznie więcej tranzystorów w jądrze o rozsądnej ekonomicznie powierzchni. Liczba tranzystorów i konsumowana przez nie energia to pewien budżet, który projektanci układu scalonego mogą „wydać” w wybrany przez siebie sposób. W Zen 2 wydano go na dwukrotnie większą pamięć podręczną, dwukrotnie szerszą część zmiennoprzecinkową i wektorową oraz na powiększenie różnych struktur związanych z wykonywaniem instrukcji poza kolejnością (OoO).
Projektanci Zen 3 nie mieli do dyspozycji tego samego środka: procesory w architekturze Zen 3 musiały być wykonane w tym samym lub bardzo podobnym procesie technologicznym, co Zen 2. Postęp w litografii już od dawna nie zapewnia regularnych, skokowych wzrostów gęstości tranzystorów i poza wyjątkowymi przypadkami nie można się już opierać głównie na nim.
Architektura Zen 3 wygląda mniej na ewolucyjne usprawnienie Zen 2, a bardziej na równoległy, ale nieco inny kierunek rozwoju Zen 1. Wspomniane środki litograficzne oraz potrzeby rynku spowodowały, że Zen 2 i Zen 3 mają bardzo dużo wspólnego w kategoriach rozmiarowych i liczbowych – po prostu wielkość różnych części procesora została ukształtowana w obu przypadkach przez podobne czynniki. Rozmiary różnych pamięci podręcznych i wewnętrznych buforów czy wysokopoziomowe cechy architektury są podobne, ale niemal każda część rdzeni x86 tych dwóch architektur różni się u podstaw.
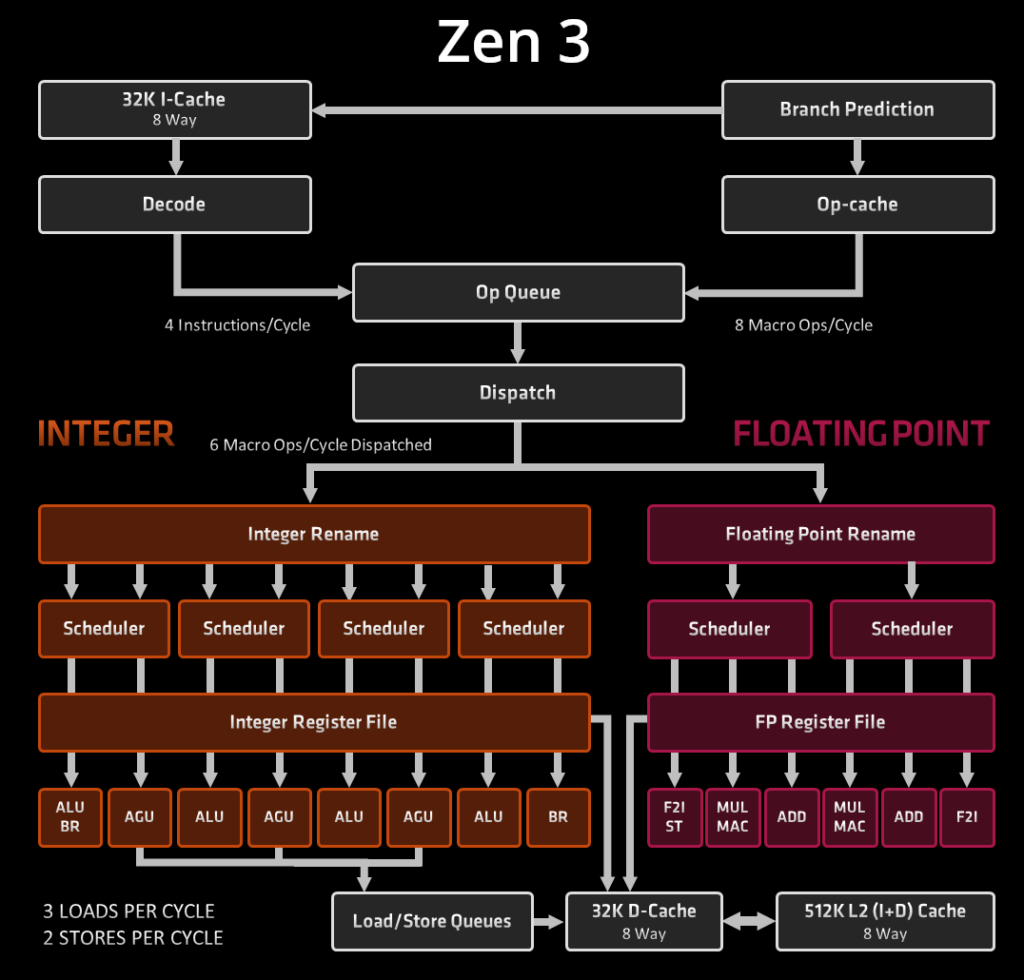
Mikroarchitektura Zen 3
Front end: zanim instrukcje zostaną wykonane
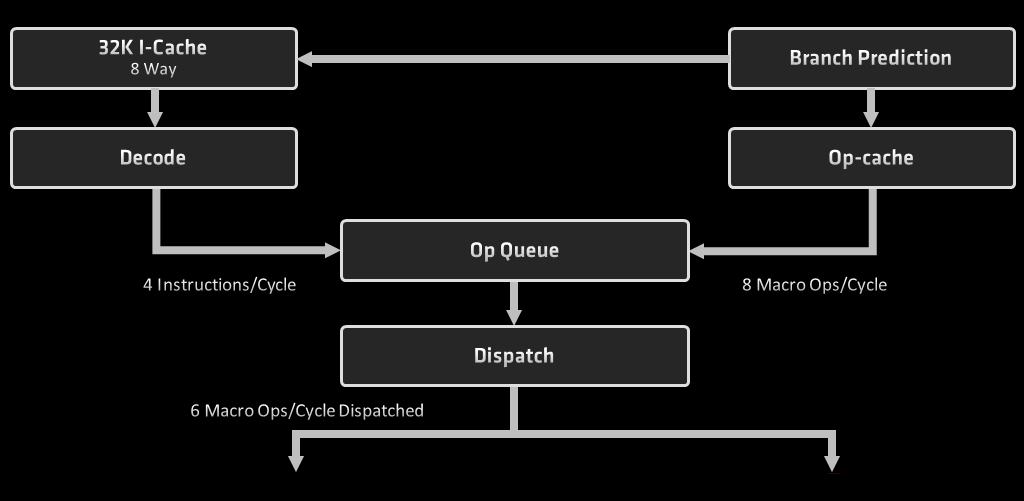
Wykonywanie programu rozpoczyna się w części front end procesora od pobrania instrukcji, zdekodowania ich i wysłania do wykonania. Na tym etapie również przewiduje się skoki. Część front end pracuje w głównej mierze sekwencyjnie – instrukcje są przetwarzane w kolejności, w jakiej występują w programie.
Procesor Zen 3 wykorzystuje do przewidywania skoków podobne techniki, co Zen 2: perceptronowy predyktor skoków w krótkich pętlach lub do nieodległych obszarów pamięci, i predyktor typu TAGE uzupełniający przewidywania tego pierwszego o znacznie dłuższą historię skoków. Przewidywanie skoków pozwala ustalić, czy dalsze instrukcje należy pobrać z pamięci L1i (i z którego miejsca), czy z pamięci zdekodowanych mikrooperacji. Układ przewidywania skoków został znacząco ulepszony, ale nie przez zmiany w algorytmie. BTB, czyli bufory przechowujące przewidziane adresy skoków zostały zbalansowane inaczej: powiększono dwukrotnie (o 512 wpisów) BTB pamięci L1, a odjęto tyle samo wpisów ze znacznie pojemniejszego BTB dla pamięci L2. Powiększono też o połowę ITA – pamięć przewidzianych adresów skoków, które w przeszłości miały różne cele. ITA przewiduje, który z nich będzie następny.
Drugie ulepszenie polega na znacznym przyspieszeniu przewidywania skoków, których cel jest w pamięci L1 lub L2. W procesorach Zen 1 i Zen 2, jeśli adres przewidzianego skoku trzeba było pobrać z BTB L1, trzeba było poczekać na niego 1 cykl zegara – to oznaczało przerwę w strumieniu instrukcji napływających do dalszych etapów potoku wykonawczego. Na adres pobierany z BTB L2 lub ITA trzeba było czekać 4 cykle. W Zen 3 to odpowiednio zero cykli (natychmiastowy wynik) i trzy cykle. Oczywiście to przyspieszenie nie zwiększa skuteczności układu przewidywania skoków. Za to znacznie zwiększa efektywność zarówno tej części potoku wykonawczego, jak i niektórych kolejnych. W typowych zastosowaniach układ przewidywania skoków poprawnie przewiduje powyżej 95% wszystkich skoków. To znaczy, że w 95% przypadków układ przewidywania Zen 3 jest o 1 cykl szybszy niż w Zen 1 i Zen 2, więc pamięć L1i, dekoder instrukcji i pamięć zdekodowanych makrooperacji rzadziej czekają, a częściej wykonują użyteczną pracę.
Pobieranie instrukcji w Zen 3 odbywa się w takich samych porcjach, jak w poprzednich Zen: porcje po 32 bajty są pobierane z pamięci podręcznej L1i i trafiają do kolejki. Kolejka między pobraniem a dekodowaniem instrukcji mieści teraz 24 takie porcje, o 1/8 więcej, niż w Zen 1 i Zen 2. Podobnie jak w architekturach Intela, w trybie SMT ta struktura jest podzielona po równo pomiędzy dwa wątki. Pobieranie instrukcji z pamięci zdekodowanych makrooperacji ma zwykle większą przepustowość, niż dekodowanie ich, choć różnica nie jest tak radykalna jak w architekturach Skylake i Sunny Cove.
Zen 1
Zen 2
Zen 3
Skylake
Sunny Cove
BTB pamięci L1
256
512
1024
?
?
BTB pamięci L2
4096
7168
6656
?
?
ITA
512
1024
1536
nd.
nd.
kolejka pomiędzy pobraniem a dekodowaniem
20
20
24
50
50
pamięć podręczna zdekodowanych operacji
2048
4096
4096
1536
2304
kolejka pomiędzy front-endem a schedulerami
72
?
?
128
140
Rozmiary różnych struktur w części front end
Operacje z dekodera lub z pamięci zdekodowanych makrooperacji (odpowiednio 4 instrukcje x86 lub 8 makrooperacji) trafiają do kolejki o nieujawnionym rozmiarze. Z niej łącznie do 6 mikrooperacji w cyklu zegara może trafić do części stałoprzecinkowej lub do części wektorowej procesora. Pod tym względem Zen 3 nie różni się od Zen 1 i Zen 2 – ta część procesora nie ogranicza wydajności niemal w żadnym przypadku.
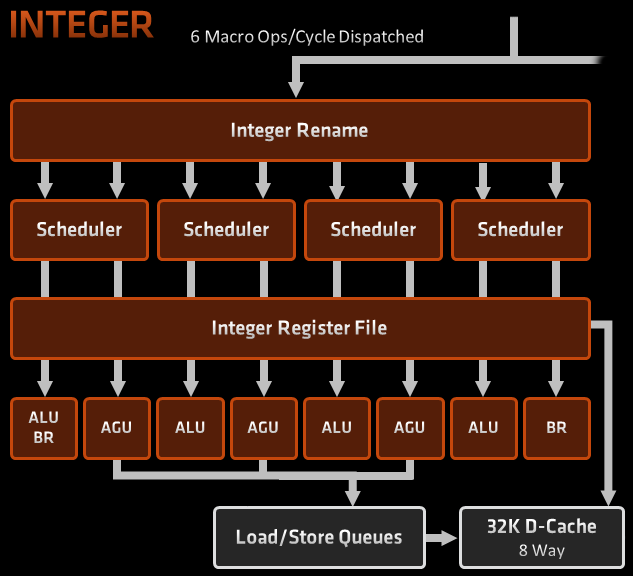
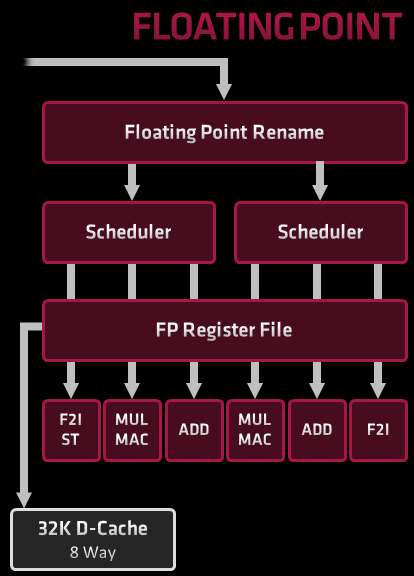
Część stałoprzecinkowa
W architekturze Zen 3 część stałoprzecinkowa procesora jest zorganizowana inaczej, niż w Zen 1 i Zen 2. W starszych architekturach AMD scheduler był podzielony na niewielkie kolejki odpowiadające jednej jednostce wykonawczej (z wyjątkiem AGU w Zen 2). Procesor miał 4 jednostki arytmetyczne i dwie (Zen 1) lub trzy (Zen 2) do obliczania adresów.
W Zen 3 scheduler jest podzielony na cztery części. Dodano jedną jednostkę wykonawczą zajmującą się wyłącznie skokami (BR na diagramie). Osiem jednostek wykonawczych jest pogrupowanych po dwie: jedna AGU lub BR i jedna innego typu. AGU w Zen 3 są całkowicie symetryczne: wszystkie mogą generować adresy pobrań i zapisów. W Zen 2 tylko dwie z trzech mogły generować adresy pobrań. Kolejki schedulowania mieszczą po 24 mikrooperacje, w sumie 96 – o 8 więcej, niż w Zen 2.
Ta zmiana organizacyjna powoduje, że choć pula rejestrów i scheduler mają tylko trochę więcej zasobów, instrukcje rzadziej czekają na zwolnienie się zasobów wykonawczych. Wszystkie jednostki wykonawcze są zajęte częściej, niż w Zen 2 czy architekturach pochodnych od Skylake, gdzie tylko wyjątkowe sekwencje instrukcji zapełniają jednocześnie wszystkie zasoby.
Okno OoO, czyli liczba instrukcji, które mogą być wykonane w dowolnej kolejności (zamiast w kolejności programu) jest w Zen 3 nieco większe, niż w Zen 2 i Skylake. Odpowiednio powiększono również pulę rejestrów do przemianowania.
Zen 1
Zen 2
Zen 3
Skylake
Sunny Cove
ROB
192
224
256
224
352
pula rejestrów INT
168
180
192
180
?
pula rejestrów FP
160
160
160
168
?
pojemność schedulera INT
84
92
96
97
160
pojemność schedulera FP
36
36
64
kolejka pobrań z pamięci
72
72
72
72
128
kolejka zapisów do pamięci
44
48
64
56
72
Część zmiennoprzecinkowa i wektorowa
W odróżnieniu od procesorów Intela, w architekturach Zen część odpowiedzialna za obliczenia zmiennoprzecinkowe i wektorowe jest odrębna od części stałoprzecinkowej: ma osobną pulę rejestrów do przemianowania, osobny scheduler, i nie dzieli żadnych zasobów z częścią stałoprzecinkową. W Zen 3 zachowano tę cechę; zachowano również 256-bitową szerokość rejestrów i jednostek wykonawczych. Zen 3 nie obsługuje instrukcji AVX512, nawet „w dwóch porcjach”, czyli w sposób, w jaki procesory Zen 1 wykonywały 256-bitowe instrukcje AVX2.
Zamiast jednego schedulera mieszczącego 36 instrukcji w Zen 3 są dwa, każdy po 32 instrukcje. Przed nimi, tak samo jak w Zen 1 i Zen 2, jest jeszcze NSQ – 64-wpisowa kolejka służąca do przyjmowania instrukcji z front-endu, ale nie uczestnicząca w rozdzielaniu i przekolejkowywaniu instrukcji.
W Zen 3 dodano dwie jednostki wykonawcze w części wektorowej: obie mogą konwertować liczby zmiennoprzecinkowe na stałoprzecinkowe, a jedna z nich może wydawać polecenia zapisu do pamięci. W ten sposób przepustowość Zen 3 w arytmetyce wektorowej jest taka sama jak Zen 2, ale jest w praktyce częściej zbliżona do maksymalnej, bo dodatkowe jednostki przejmują nie-arytmetyczne instrukcje i odciążają te zajmujące się dodawaniem i mnożeniem.
Wiele instrukcji zmiennoprzecinkowych jest wykonywanych szybciej, niż w Zen 2. Zen 3 może wykonać dwa FMA, czyli mnożenia połączone z dodawaniem, w jednym cyklu, a wynik jest otrzymywany po 4 cyklach – to o 1 szybciej, niż w Zen 2. Przepustowość i prędkość 256-bitowych FMA w Zen 3 jest taka sama, jak w rdzeniach Intela. Przepustowość dzielenia, pierwiastkowania i instrukcji AES jest do dwóch razy większa (zależnie od operandów).
Pobranie i zapis do pamięci podręcznej
Jedną z największych innowacji w Zen 3 są zwiększone możliwości zapisu i odczytu z pamięci. Rdzeń Zen 3 może wykonać 3 operacje na pamięci w cyklu zegara. Teoretycznie to tyle samo, co w Zen 2, ale Zen 3 znacznie częściej zbliża się do tego limitu dzięki sprawniejszemu schedulowaniu operacji generowania adresów. Maksymalnie 2 z tych 3 operacji mogą być zapisami. W praktyce nie stanowi to ograniczenia, bo większość instrukcji generuje 1 wynik z 1 lub 2 operandów – danych wejściowych jest średnio więcej, niż wyjściowych.
Maksymalna liczba…
Zen 1
Zen 2
Zen 3
Skylake
Sunny Cove
…operacji na pamięci/cykl
2
3
3
3
4
…zapisów/cykl
1
1
2
1
2
…odczytów/cykl
1
2
3
2
2
Ta zmiana powiększa efektywność ogromnej pamięci podręcznej – przepustowość cache jest częściej wykorzystywana w pełni.
Zen 3 to druga po Sunny Cove mikroarchitektura, która może wykonać dwa zapisy na cykl, i pierwsza, która może wykonać trzy odczyty na cykl. To duża i zasadnicza zmiana, której od wielu lat nie było w procesorach x86. Nie spodziewamy się podobnego zwiększenia możliwości przez kolejnych kilka lat. Następne ulepszenie pod tym względem będzie prawdopodobnie związane z poszerzeniem obliczeń wektorowych. Podane powyżej limity dotyczą operacji o szerokości 64 bitów (podstawowa szerokość operandów w 64-bitowym procesorze). Zen 3 może wykonać 1 128-bitowy lub 256-bitowy zapis oraz 2 128-bitowe lub 256-bitowe pobrania w cyklu. Jeśli przyszłe wersje architektury Zen będą obsługiwać instrukcje AVX512, zapewne możliwości generowania adresów pozostaną takie same, jak do tej pory, ale przepustowość pamięci podręcznych wzrośnie, żeby zaspokoić potrzeby szerokich jednostek wektorowych.
Makroarchitektura: 8 rdzeni w jednym CCX
Poza rdzeniami x86 zmieniła się właściwie tylko jedna cecha budowy całego procesora Zen 3: wspólna pamięć podręczna L3. W Zen 1 i Zen 2 cztery rdzenie były zgrupowane w CCX (core complex) razem ze wspólnym dla nich blokiem pamięci podręcznej. W Zen 3 osiem rdzeni tworzy jedną grupę (CCX).
Zen 1
Zen 2
Zen 3
Pamięć L3 wspólna dla…
4 rdzeni
4 rdzeni
8 rdzeni
Pojemność L3 w CCX
8 MB
16 MB
32 MB
Pojemność L3 na 1 rdzeń
2 MB
4 MB
4 MB
Pojemność pamięci podręcznej w stosunku do liczby rdzeni jest taka sama, jak w Zen 2 – ta wielkość jest uwarunkowana względami ekonomicznymi i techniką produkcji.
Pamięć podręczna jest zarządzana sprzętowo i „niewidzialna” dla oprogramowania. Oprogramowanie „widzi” dużą, jednolitą przestrzeń adresową całej pamięci operacyjnej. Jedynym efektem działania cache jest to, że dostęp do niektórych części przestrzeni adresowej jest znacznie szybszy – to te części, które w danej chwili były zduplikowane w cache i nie trzeba było po nie sięgać do znacznie wolniejszego RAM-u. Pojemność L3 dostępna dla jednego wątku jest jednak dwa razy większa. Jeśli dane nie zostaną odnalezione w lokalnej pamięci L3, zapytanie zostaje wysłane do innych CCX. Przesłanie ich stamtąd jest szybsze, niż z RAM-u, ale to nie jest główny powód: po prostu pamięć podręczna musi być spójna, czyli wszystkie CCX muszą pod tym samym adresem logicznym widzieć tę samą treść.
Pamięć jest też jedynym sposobem na komunikację dwóch wątków: jeden z nich zapisuje jakiś komunikat pod pewnym adresem, a drugi może go odczytać z tego samego miejsca. W wielowątkowej maszynie nie ma innego, bezpośredniego kanału komunikacji między programami przypisanymi do różnych procesorów. Wspólna pamięć podręczna zmniejsza zatem opóźnienie w komunikacji między wątkami.
Czemu nie dało się tego zrobić wcześniej?
Możemy spekulować, dlaczego nie zmieniono organizacji CCX wcześniej, albo czemu w ogóle zaczęto od pogrupowania rdzeni właśnie po cztery.
Do połączenia rdzeni i segmentów cache L3 w architekturze Zen 2 wykorzystano crossbar, czyli strukturę połączeń umożliwiającą komunikację każdy-z-każdym. Im więcej wejść i wyjść ma crossbar, tym bardziej skomplikowana jest struktura tych połączeń. Wygodnym uproszczeniem jest wyobrażenie sobie przekątnych wielokąta: ich liczba rośnie proporcjonalnie do kwadratu liczby wierzchołków. Zbudowanie crossbara łączącego 8 rdzeni z 8 segmentami pamięci cache jest znacznie trudniejsze, wymaga więcej połączeń i większej powierzchni jądra, niż podobny schemat połączeń dla 4 rdzeni i 4 segmentów cache. Inżynierowie AMD mieli już doświadczenie z crossbarami dla 4 rdzeni – zbudowali je dla procesorów Interlagos (Opteron w architekturze Bulldozer) i Jaguar (m. in. procesory w konsolach Xbox One i PlayStation 4), i być może woleli zacząć od znanego problemu. AMD nie ujawnia, czy segmenty L3 i rdzenie są w Zen 3 nadal połączone za pomocą crossbara. Test opóźnienia w dostępie do cache nie pozwala wykluczyć pewnego rodzaju dwukierunkowej magistrali pierścieniowej, podobnej do architektur Intela.
Udostępnienie jednej puli pamięci cache aż ośmiu rdzeniom odbyło się kosztem opóźnienia: na dostęp do cache L3 w Zen 3 trzeba czekać średnio 46 cykli zegara, w porównaniu do ok. 39 cykli w Zen 2 i ok. 35 cykli w Zen 1. Być może powiększenie tego opóźnienia byłoby zbyt wielkim obciążeniem dla Zen 1 i Zen 2 z ich mniej sprawnymi systemami pobierania z wyprzedzeniem i mniejszymi możliwościami zapisywania i odczytywania z pamięci w jednym cyklu.
Podsumowanie
Architektura Zen 3 jest pod pewnymi względami demonstracją alternatywnej historii rozwoju Zen 1. Jedną wersją była architektura Zen 2, w której większość ulepszeń była ilościowa i wynikała ze zmiany procesu technologicznego – projektanci procesora mieli do dyspozycji więcej tranzystorów, które przeznaczono na powiększenie pamięci podręcznej i poszerzenie części wektorowej i zmiennoprzecinkowej procesora.
Zen 3 jest alternatywną wersją – ma wiele tych samych cech ilościowych, bo również pochodzi od Zen 1 i również wykorzystuje proces technologiczny klasy 7 nm. To, co było rozsądnym sposobem na „wydanie” pewnej liczby tranzystorów czy pewnego budżetu energetycznego w Zen 2 jest również rozsądne w Zen 3, i dlatego wiele cech tych architektur jest wspólnych. Jednak w Zen 3 poczyniono znacznie więcej zmian algorytmicznych, a korzyści płynące z nowej techniki litograficznej spożytkowano nie tylko na proste zmiany ilościowe, ale na istotne ulepszenia logiczne:
przyspieszenie najwolniejszych operacji zmiennoprzecinkowych i wektorowych, w tym FMA,
radykalne ulepszenie przewidywania skoków,
radykalne powiększenie przepustowości w operacjach na pamięci,
poszerzenie rdzenia o trzy jednostki wykonawcze,
poprawienie efektywności schedulerów w obu częściach procesora.
Niespodziewanie duży wzrost wydajności względem procesorów Zen 2 jest zasługą tych zmian oraz zorganizowania rdzeni i pamięci podręcznej L3 w grupy po 8, zamiast po 4. W następnym artykule przyjrzę się bliżej organizacji pamięci podręcznych, opóźnieniu w komunikacji między rdzeniami oraz budowie całego procesora.
Źródła:
Clark, M., Zen 3 Architecture – Deep Dive, AMD 2020.
Dundas J. D., Zuraski G. D., Snyder T. R.: High performance zero bubble conditional branch prediction using micro branch target buffer. USA. Opis patentowy US20170068539A1, opublikowany 09.03.2017.